· frameworks · 6 min read
Advanced AdonisJS: Tips for Scaling Your Application Effectively
Practical techniques and architecture patterns for scaling AdonisJS apps - from choosing a scalable architecture and optimizing Lucid queries to caching, job queues, WebSocket strategies, deployment patterns, and observability.
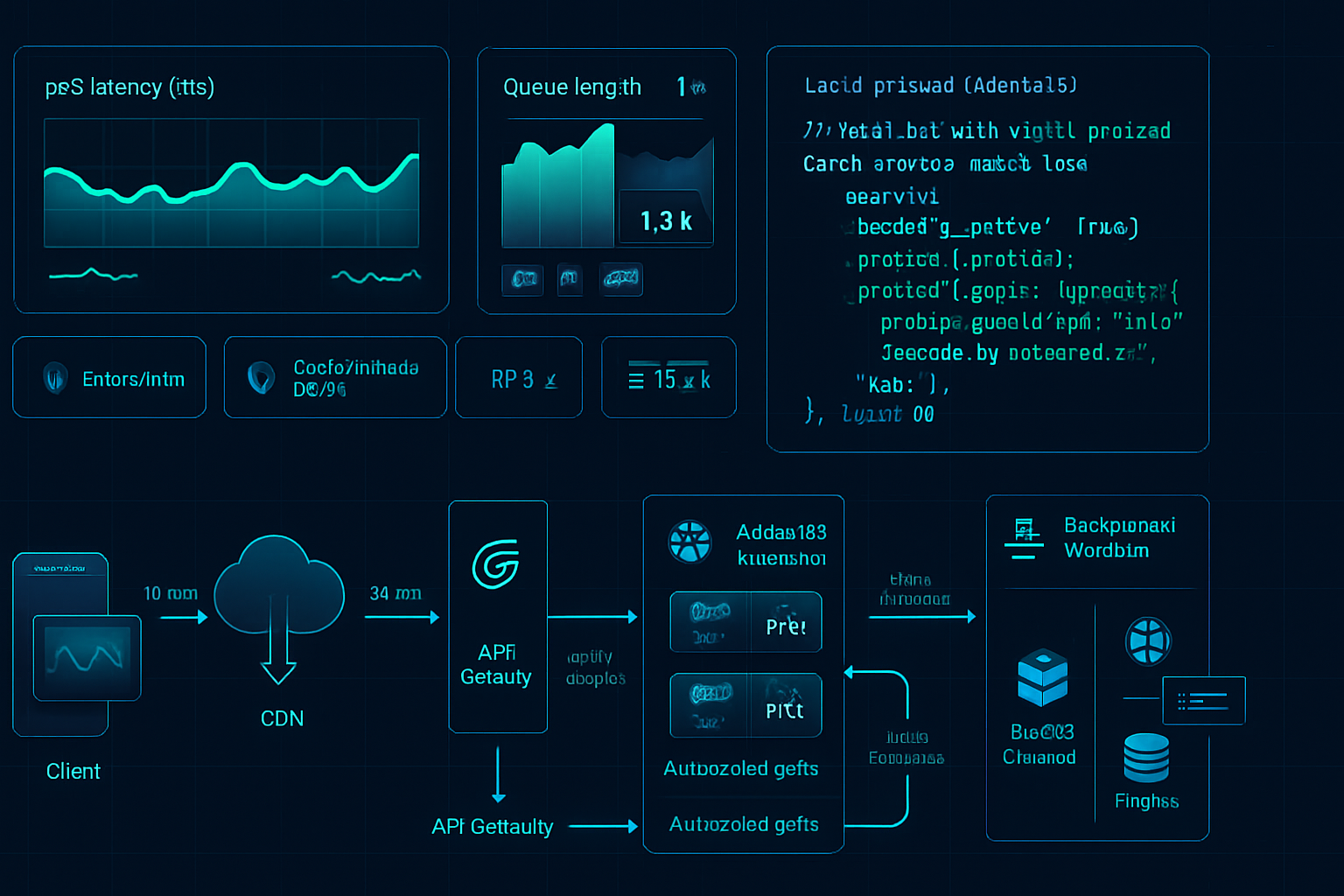
Outcome first: by the end of this article you’ll have a clear checklist and concrete techniques to scale your AdonisJS application safely - horizontally and vertically - while keeping latency low, costs predictable, and development velocity high.
Why this matters. AdonisJS gives you a great developer experience for building server-side apps on Node.js, but growth exposes new constraints: database bottlenecks, slow queries, background-job pileups, WebSocket fanouts, and deployment complexity. The patterns below let you remove those chokepoints without rewriting your app from scratch.
1. Measure before optimizing
Start with data. Identify the real bottlenecks with metrics and load tests - don’t guess.
- Use a load testing tool (k6, Artillery) to reproduce expected traffic.
- Capture latency percentiles (p50/p95/p99), error rates, queue length, DB contention.
- Record traces for slow requests.
References: k6 (https://k6.io/), Artillery (https://www.artillery.io/), OpenTelemetry (https://opentelemetry.io/)
2. Choose the right architecture pattern
Pick the simplest architecture that satisfies your growth plan. Common patterns:
- Modular monolith: Keep one deployable app but split into modules (Auth, Billing, Catalog). Easiest to maintain early on.
- Microservices: Split by bounded contexts when teams and scaling needs justify it. Good for independent scaling and deployments.
- Service-oriented with API Gateway: Use a lightweight gateway for routing, rate-limiting, auth, and TLS termination.
When to split: high independent traffic per domain, differing scaling characteristics, or different SLAs.
3. Make your Adonis app stateless where possible
Stateless services scale horizontally easily. Strategies:
- Move session state to a shared store (Redis, Memcached) or use signed JWTs for auth.
- Persist file uploads in object storage (S3/compatible) instead of local disk.
- Store ephemeral locks and feature flags in Redis.
Tip: If you must keep sticky sessions (for old WebSocket designs), use a sticky load balancer or change to shared session storage.
4. Database scaling and query performance
Databases are the most common scaling bottleneck. Tackle them across these axes:
- Optimize queries
- Use Lucid eager loading to avoid N+1 problems:
// Avoid N+1
const users = await User.query().preload('posts');
// Count relation efficiently
const usersWithCount = await User.query().preload('posts', query => {
query.select('id');
});- Use pagination (cursor-based for large datasets) and streaming/chunking for batch jobs:
await Database.from('big_table').chunk(1000, async rows => {
// process a batch of rows
});- Indexing
- Add proper indexes for WHERE and JOIN columns. Monitor slow queries and add indexes selectively.
- Connection pooling
- Configure an appropriate pool size in config/database.ts. Too many DB connections can overwhelm the DB; too few creates queuing in the app.
Example (conceptual) database pool config:
// config/database.ts
pg: {
connectionString: env('DATABASE_URL'),
pool: { min: 2, max: 20 },
}- Read scaling
- Use read replicas for read-heavy workloads. Route readonly queries to replicas; keep writes to the primary.
- Be aware of replication lag-either design eventual consistency or read-after-write routing to primary.
- Sharding and partitioning
- For very high scale, consider logical sharding (by customer, tenant) or DB partitioning (Postgres table partitioning).
- Use transactions sensibly
- Keep transactions short. Don’t open a transaction for long-running work.
References: Postgres replication and partitioning docs (https://www.postgresql.org/docs/current/)
5. Caching strategies
Caching reduces latency and DB load but adds complexity. Common patterns:
- CDN for static assets - offload images, JS/CSS, and public files to a CDN.
- HTTP caching - set cache-control headers for cacheable endpoints.
- Redis for application caching and session store.
- Query result caching - store expensive query results with a TTL, and invalidate on writes.
Example cache pattern (pseudo-code):
const cacheKey = `user:${id}:profile`;
const cached = await Cache.get(cacheKey);
if (cached) return cached;
const profile = await User.find(id);
await Cache.set(cacheKey, profile, 60); // ttl 60s
return profile;Cache invalidation strategies:
- Write-through or write-behind as needed.
- Use short TTLs for highly dynamic data.
- Use versioned keys or pub/sub invalidation when updating many consumers.
Redis docs: https://redis.io/
6. Background jobs and queues
Move slow, non-blocking tasks off the request path: email sending, image processing, reports.
- Use a robust queueing system (BullMQ, RabbitMQ, etc.). Adonis integrates well with Redis-backed queues.
- Scale workers separately from web processes.
- Monitor queue lengths and job failure rates.
Example (conceptual) worker with BullMQ:
// producer
await queue.add('process-image', { imageId });
// worker
const worker = new Worker('default', async job => {
await processImage(job.data.imageId);
});Keep job handlers idempotent. Use retries with exponential backoff and dead-letter queues for poison jobs.
Reference: BullMQ (https://docs.bullmq.io/)
7. Scaling real-time (WebSockets) and pub/sub
Real-time systems require special handling:
- Don’t rely on in-memory socket state if you need horizontal scaling.
- Use a pub/sub adapter (Redis) to broadcast events across multiple process instances.
- Alternatively, use a managed real-time service (Pusher, Ably, or a managed WebSocket gateway).
For WebSocket or Socket.IO scaling, use the Redis adapter to propagate messages between nodes.
8. Node/Process-level optimizations and clustering
- Use a process manager (PM2) or systemd to run multiple Node workers per host and handle restarts.
- Use Node’s cluster mode or PM2 cluster to utilize multiple CPU cores.
Example PM2 ecosystem file (conceptual):
{
"apps": [
{
"name": "adonis-app",
"script": "node/build/server.js",
"instances": "max",
"exec_mode": "cluster",
"env": { "NODE_ENV": "production" }
}
]
}- Configure health checks and graceful shutdown so in-flight requests finish before the instance terminates.
9. Containerization and orchestration
- Containerize using Docker for consistent deploys. Keep images small and multi-stage.
- Use Kubernetes (or ECS/GKE) to scale pods. Benefits: auto-scaling, rolling updates, liveness/readiness probes.
- Use Horizontal Pod Autoscaler (HPA) based on CPU/requests or custom metrics (queue length).
Deployment patterns: blue-green or canary deploys reduce risk for traffic-sensitive changes.
References: Kubernetes docs (https://kubernetes.io/)
10. Observability: logs, metrics, tracing
Make observability part of your scaling plan:
- Structured logs (JSON) ship to a centralized store (ELK, Loki).
- Metrics: expose Prometheus metrics for request rates, latency, DB pool usage, queue sizes.
- Distributed tracing (OpenTelemetry): trace request flows across services (HTTP, DB, queues).
When latency spikes, traces point to the cause faster than guesswork.
11. Security and rate limiting at scale
- Apply rate limits at API gateway or reverse proxy (NGINX, Cloudflare) to protect downstream services.
- Use WAFs and API gateways for DDoS protection and to centralize auth and CORS.
- Hardening and monitoring are essential as your attack surface grows.
12. CI/CD, testing and schema migrations
- Automate build, test, and deploy pipelines. Run load tests and smoke tests as part of CI.
- Migrate databases using safe, incremental migrations (avoid long locks). For big migrations use zero-downtime strategies: backfill columns, deploy code that can handle both schemas, then remove old artifacts.
13. Practical checklist (quick wins)
- Add request/DB/queue metrics and tracing.
- Fix top 5 slow queries (indexes, eager loads).
- Introduce Redis for caching sessions and hot queries.
- Offload heavy work to BullMQ workers; scale them independently.
- Containerize; use PM2 or K8s with readiness probes.
- Set up read replicas and route readonly queries.
- Configure CDN for static assets.
14. Recommended stack components
- Reverse proxy / TLS: NGINX / Cloudflare
- Process manager: PM2 (cluster mode) or Docker+K8s
- Queue: BullMQ (Redis-backed)
- Cache & session store: Redis
- Database: Postgres (primary + read replicas); consider partitioning for very large tables
- Observability: Prometheus + Grafana, OpenTelemetry traces, centralized logs (ELK/Loki)
Final thoughts
Scaling AdonisJS isn’t about making a single component insanely fast. It’s about finding where work accumulates and removing friction there: move slow work out of request paths, make services stateless, add caching wisely, and scale components independently. Measure, iterate, and automate - and your AdonisJS app will stay fast as traffic grows.
References
- AdonisJS docs: https://docs.adonisjs.com/
- BullMQ: https://docs.bullmq.io/
- Redis: https://redis.io/
- PM2: https://pm2.keymetrics.io/
- Kubernetes: https://kubernetes.io/
- OpenTelemetry: https://opentelemetry.io/



